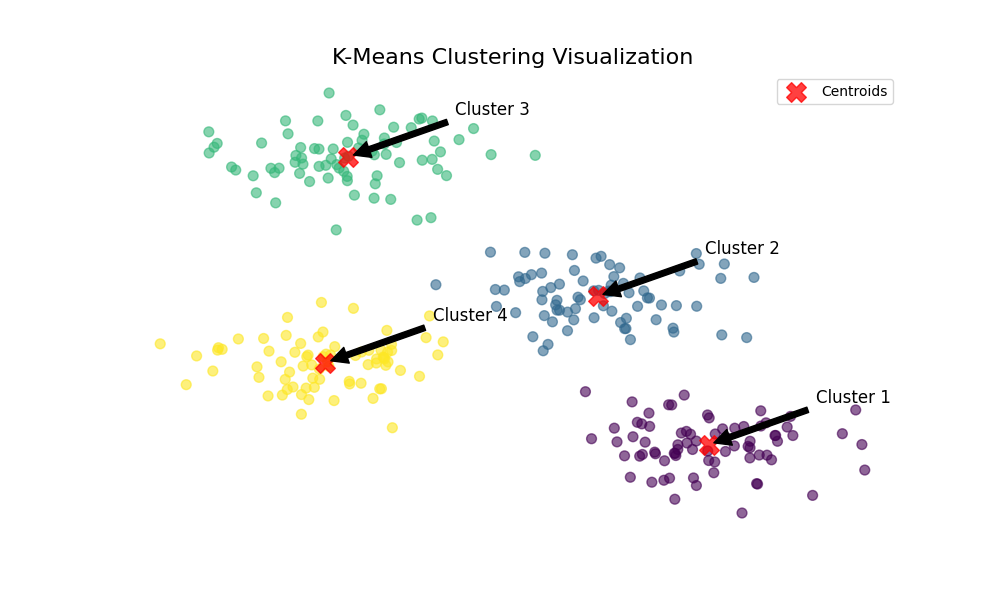
Clustering is a powerful unsupervised learning technique in data science, used to group similar data points into distinct clusters. It helps in uncovering inherent structures within data by organizing it into meaningful segments without predefined labels. By examining the feature similarities, clustering algorithms partition datasets based on how closely related the data points are. This technique is widely applied in various fields, including marketing, biology, image processing, and social network analysis, due to its ability to reveal insights and patterns that may not be immediately visible.
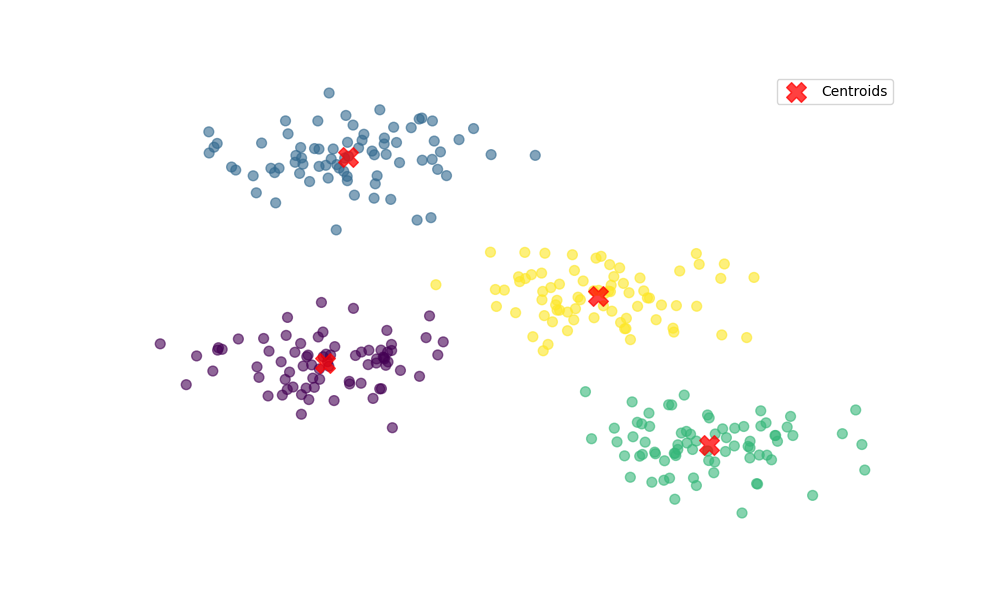
Now that we’ve introduced the core idea behind clustering, let’s delve deeper into its various algorithms, how they work, and the key concepts that underpin this essential technique.
Clustering is an unsupervised machine learning technique that aims to group a set of objects in such a way that objects in the same group (or cluster) are more similar to each other than to those in other groups. It is widely used for data analysis and pattern recognition, helping to identify hidden structures in data. The fundamental premise of clustering is that the data can be divided into subsets where members of each subset exhibit high similarity.
In essence, clustering simplifies data analysis by reducing the complexity of datasets and revealing natural groupings within the data. Its flexibility and interpretability make it a popular choice for exploratory data analysis.
Key concepts that help define clustering techniques include:
Clustering can be broadly categorized into different types based on how the clusters are formed: